
Python - Pandas 2
분석하기 좋은 데이터
- 데이터 분석 목적에 맞는 데이터를 모아 새로운 표를 만들어야 함
- 측정한 값은 행(row)을 구성
- 변수는 열(column)을 구성
데이터 연결하기
concat 메소드로 데이터를 연결할 수 있다.
import pandas as pd
df1 = pd.read_csv('Python/doit_pandas-master/data/concat_1.csv')
df2 = pd.read_csv('Python/doit_pandas-master/data/concat_2.csv')
df3 = pd.read_csv('Python/doit_pandas-master/data/concat_3.csv')
row_concat = pd.concat([df1, df2, df3])
print(df1)
print('***********************************')
print(df2)
print('***********************************')
print(df3)
print('***********************************')
print(row_concat)
위의 사진과 같이 df1, df2, df3 세개의 데이터 프레임의 정보를 ***선을 기준으로 출력하였다.
concat 메소드를 사용하면
해당 사진과 같이 인덱스도 그대로 유지한 채 하나의 데이터 프레임으로 출력되는 것을 확인할 수 있다.
*concat 메소드는 전달받은 리스트의 요소 순서대로 데이터를 연결한다.
그렇다면 기존의 df1와 새로운 시리즈를 연결하면 어떻게 될까?
new_row_Series = pd.Series(['n1','n2','n3','n4'])
print(pd.concat([df1, new_row_Series]))결과를 보면 df1에 해당하는 값 하단과 우측에 NaN이 있음을 확인할 수 있다.
이것은 위에 0123 인덱스 (df1)에 해당하는 값이 없기에 NaN 값이 들어가있으며
new_row_Series에 해당하는 값이 없는 곳 역시 NaN 값이 들어가있는 것이다.
NaN은 누락값이라 한다.
이러한 문제가 있는데 결론은 행이 1개더라도 반드시 데이터프레임에 담아 연결을 해야한다.
누락값이 존재하는 이상 정확한 데이터 분석에 영향을 미칠 수 있기 때문이다.
시리즈를 데이터프레임의 새로운 행으로 연결하려하면 시리즈엔 열 이름이 없기 때문에 새로운 열로 간주하여 D 옆의 0이라는 열이 새로 생긴 것을 확인할 수 있다.
데이터프레임으로 바꾸어 연결해보면
new_row_Series = pd.DataFrame([['n1','n2','n3','n4']], columns=['A','B','C','D'])
print(pd.concat([df1, new_row_Series]))이와 같은 결과가 나온다.
이 역시 행 번호에 문제점이 있는데 01234가 아닌 01230으로 행 번호에 문제가 생긴다.
이러한 문제점은
new_row_Series = pd.DataFrame([['n1','n2','n3','n4']], columns=['A','B','C','D'])
print(df1.append(new_row_Series,ignore_index=True))이와 같이 연결할 데이터 프레임이 1개인 경우 append 메소드를 이용해 연결을 하며 ignore_index=True로 인자를 줄 경우 데이터프레임의 인덱스를 0부터 다시 지정하며 해결할 수 있다.
만일 행이 아닌 열 방향으로 데이터를 합칠 경우에는 어떻게 하면 될까?
concat의 default 값은 행 방향 데이터 연결이다.
옵션으로 axis=1의 경우 열 방향으로 데이터를 연결한다.
ow_concat = pd.concat([df1, df2, df3], ignore_index=True)
col_concat = pd.concat([df1, df2, df3],axis=1, ignore_index=True)
#행 방향
print(row_concat)
#열 방향
print(col_concat)
공통 열과 공통 인덱스만 연결하기
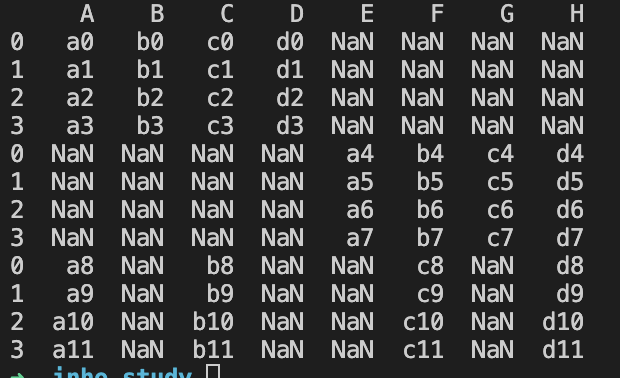
만일 열 이름의 일부가 서로 다른 데이터 프레임을 연결할 경우 열 이름이 정렬되며 연결되지만 데이터 프레임에 없는 열 이름의 데이터는 누락값으로 처리되어 버린다.
누락값 예시
df1.columns=['A','B','C','D']
df2.columns=['E','F','G','H']
df3.columns=['A','C','F','H']
row_concat = pd.concat([df1,df2,df3])
print(row_concat)df1~3의 열 이름을 다시 지정해주었다.
누락값이 없이 데이터를 연결하는 방법은 공통 열만 골라 연결하면 누락값이 생기지 않을 것이며 이는 join 인자를 inner로 지정하면 해결된다.
df1, df3의 공통열만 연결한 것이다.
df1,df2,df3 세 데이터프레임 모두를 공통열만 연결하기엔 3가지 데이터프레임의 열 교집합이 없기 때문에 불가능하다.
row_concat = pd.concat([df1, df3],join='inner', ignore_index=True)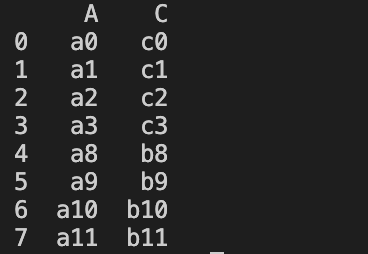
merge 메소드
내부조인 : 둘 이상의 데이터프레임에서 조건에 맞는 행을 연결하는 것
merge 메소드는 기본적으로 내부 조인을 실행하며 메소드를 사용한 데이터프레임을 왼쪽으로 지정하고 첫번째 인자값으로 지정한 데이터프레임을 오른쪽으로 지정한다. left_on, right_on 인자는 값이 일치해야할 데이터프레임의 열을 지정한다,
즉 왼쪽 데이터프레임의 열과 오른쪽 데이터프레임의 열의 값이 일치할경우 왼쪽 데이터프레임을 기준으로 연결한다.

예시로 site 데이터프레임(위) visited_subset(아래)의 열중 데이터가 일치하는 열은 site의 name visited_subset의 site이다.
import pandas as pd
person = pd.read_csv('Python/doit_pandas-master/data/survey_person.csv')
site = pd.read_csv('Python/doit_pandas-master/data/survey_site.csv')
survey = pd.read_csv('Python/doit_pandas-master/data/survey_survey.csv')
visited = pd.read_csv('Python/doit_pandas-master/data/survey_visited.csv')
visited_subset = visited.loc[[0,2,6],]
o2o_merge = site.merge(visited_subset, left_on='name', right_on='site')
print(o2o_merge)
위의 사진은 visisted_subset을 오른쪽으로 지정한다. site(왼쪽 데이터프레임)의 name열과 visted_subset의 name열의 값이 일치하기 때문에 왼쪽 데이터프레임을 기준으로 연결됐다.